
Java 8 brought us tools like CompletableFuture and Stream API… let’s try to combine them both and create a Stream that returns values from a collection of CompletableFutures as they arrive.
This approach was used when developing 1.0.0 of parallel-collectors.
Streaming CompletableFutures
Essentially, what are trying to do is to implement a solution that would allow us to convert a collection of futures into a stream of values returned by those futures:
Collection<CompletableFuture<T>> -> Stream<T>
In the world of Java, that could be achieved by using, for example, a static method:
public static <T> Stream<T> inCompletionOrder(Collection<CompletableFuture<T>> futures) {
// ...
}To create a custom Stream, one needs to implement a custom java.util.Spliterator:
final class CompletionOrderSpliterator<T>
implements Spliterator<T> { ... }And now, we can finish up with the implementation of our static method:
public static <T> Stream<T> completionOrder(Collection<CompletableFuture<T>> futures) {
return StreamSupport.stream(
new CompletionOrderSpliterator<>(futures), false);
}That’s the easy part, let’s implement the CompletionOrderSpliterator now.
Implementing CompletionOrderSpliterator
To implement our Spliterator, we’ll need to fill in the blanks provide custom implementations of the following methods:
final class CompletionOrderSpliterator<T> implements Spliterator<T> {
CompletionOrderSpliterator(Collection<CompletableFuture<T>> futures) {
// TODO
}
@Override
public boolean tryAdvance(Consumer<? super T> action) {
// TODO
}
@Override
public Spliterator<T> trySplit() {
// TODO
}
@Override
public long estimateSize() {
// TODO
}
@Override
public int characteristics() {
// TODO
}
}Naturally, we need a proper constructor as well.
The most natural way of approaching the problem would involve making a working copy of the source collection, waiting for any future to complete, removing it from the collection and feeding it to the Spliterator itself.
Waiting for any future to complete can be quickly done using CompletableFuture#anyOf, and it handles exception propagation correctly out of the box.
However, there’s a slight complication.
If you look at the signature of CompletableFuture#anyOf, you will see that it’s not very practical because it accepts multiple CompletableFutures<?> and returns a single CompletableFuture<Object>, but this is not the main issue here (just a slight inconvenience).
The real problem is that the CompletableFuture<Object> returned by the method is not the future that completed first, but a new CompletableFuture instance that completes when any future completes.
This makes the whole idea of waiting for a future and then removing it from a list of remaining futures a bit complicated. We can’t rely on reference equality, so we can either do a linear scan after each signal from CompletableFuture#anyOf, or try to come up with something better.
The naive solution could look like:
private T takeNextCompleted() {
anyOf(futureQueue.toArray(new CompletableFuture[0])).join();
CompletableFuture<T> next = null;
for (CompletableFuture<T> future : futureQueue) {
if (future.isDone()) {
next = future;
break;
}
}
futureQueue.remove(next);
return next.join();
}I’m doing a linear scan and store the index for the sake of constant-time removal. If you want to know why I’m passing 0 to the CompletableFuture[] although I know what the size is, check this article.
If you look at the problem from a pragmatic point of view, this should be good enough since no one would ever expect to iterate on a collection of futures that’s more than 10-20 thousand in size because of the hardware thread-count limitations (actual number can vary a lot depending on multiple factors, for example, stack size).
However, CompletableFutures are not bound to threads (one thread can complete an unlimited number of futures), plus once the Project Loom goes live, the same number of threads will be able to handle a higher number of parallel computations.
Still, 20000 iterations would result in visiting anything between 20000 nodes optimistically(it’s always the first future that completes) to 200000000 nodes pessimistically.
What could we do about it if we can’t rely on referential equality or hashcodes of CompletableFutures?
We could assign our ids to them and store them in a map along with matching futures and then make futures identify themselves by returning indexes alongside actual values by returning a pair.
So, let’s store our futures in a map:
private final Map<Integer, CompletableFuture<Map.Entry<Integer, T>>> indexedFutures;
Now, we could manually assign ids from a monotonically increasing sequence, and make futures return them as well:
private static <T> Map<Integer, CompletableFuture<Map.Entry<Integer, T>>> toIndexedFutures(List<CompletableFuture<T>> futures) {
Map<Integer, CompletableFuture<Map.Entry<Integer, T>>> map
= new HashMap<>(futures.size(), 1); // presizing the HashMap since we know the capacity and expected collisions count (0)
int seq = 0;
for (CompletableFuture<T> future : futures) {
int index = seq++;
map.put(
index,
future.thenApply(
value -> new AbstractMap.SimpleEntry<>(index, value)));
}
return map;
}And now, we can find and process the next completed future by waiting for it, reading the sequence number and then using it to remove the future from the list of remaining ones:
private T nextCompleted() {
return anyOf(indexedFutures.values()
.toArray(new CompletableFuture[0]))
.thenApply(result -> ((Map.Entry<Integer, T>) result))
.thenCompose(result -> indexedFutures.remove(result.getKey()))
.thenApply(Map.Entry::getValue)
.join();
}Implementation of tryAdvance() becomes trivial:
@Override
public boolean tryAdvance(Consumer<? super T> action) {
if (!indexedFutures.isEmpty()) {
action.accept(nextCompleted());
return true;
} else {
return false;
}
}The hardest part is behind us, now we need to implement three remaining methods:
@Override
public Spliterator<T> trySplit() {
return null; // because splitting is not allowed
}
@Override
public long estimateSize() {
return indexedFutures.size(); // because we know the size
}
@Override
public int characteristics() {
return
SIZED // because we know the size upfront
& IMMUTABLE // because the source can be safely modified
& NONNULL; // because nulls in source are not accepted
}And here we are.
Working Example
We can quickly validate that it works appropriately by introducing a random processing lag when going through a sorted sequence:
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(10);
List<CompletableFuture<Integer>> futures = Stream
.iterate(0, i -> i + 1)
.limit(100)
.map(i -> CompletableFuture.supplyAsync(
withRandomDelay(i), executorService))
.collect(Collectors.toList());
completionOrder(futures)
.forEach(System.out::println);
}
private static Supplier<Integer> withRandomDelay(Integer i) {
return () -> {
try {
Thread.sleep(ThreadLocalRandom.current()
.nextInt(10000));
} catch (InterruptedException e) {
// ignore shamelessly, don't do this on production
}
return i;
};
}And you can see that values get returned not in the original order:
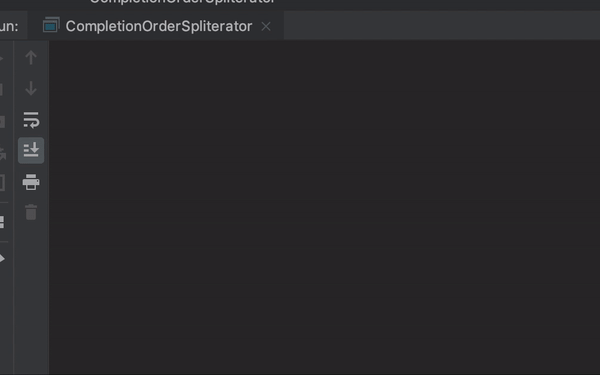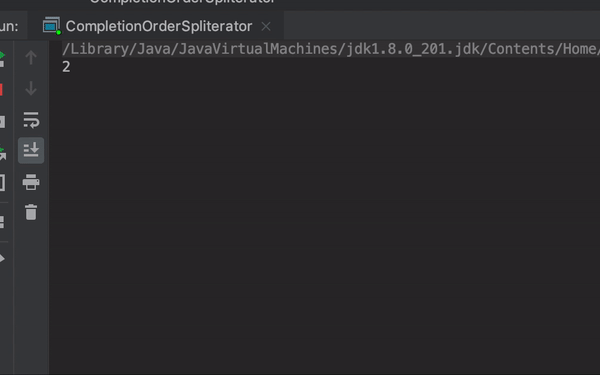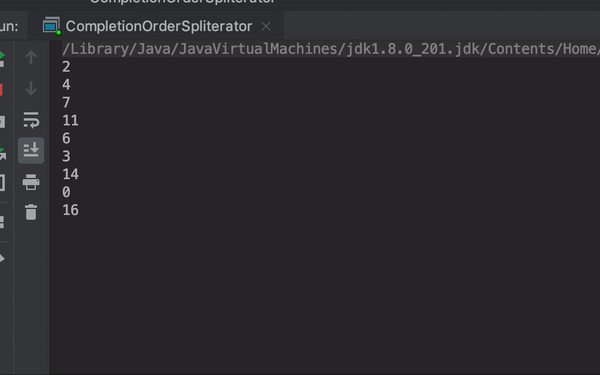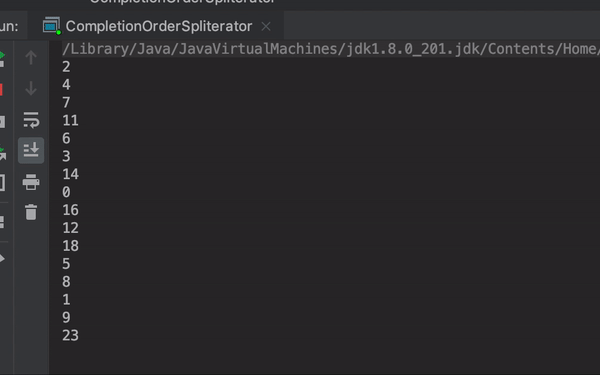
6 5 2 4 1 11 8 12 3
Streaming Futures in Original Order
What if we want different semantics and simply maintain the original order?
Luckily, that can be achieved quickly without any particular infrastructure:
public static <T> Stream<T> originalOrder(
Collection<CompletableFuture<T>> futures) {
return futures.stream().map(CompletableFuture::join);
}Improving Performance
Over time, I figured out another solution to the same problem involving just a simple blocking queue and CompletableFuture’s callback support.
Simply put, I’d make CompletableFutures add themselves to a blocking queue straight after the completion removing the need for associating them with sequence numbers:
futures.forEach(f -> f.whenComplete((t, __) -> completed.add(f)));
This drastically reduces the complexity and the amount of preprocessing that needs to be done since now we just need to wait for the result to arrive in the queue, and simply take them from there:
final class CompletionOrderSpliterator2<T> implements Spliterator<T> {
private final int initialSize;
private final BlockingQueue<CompletableFuture<T>> completed = new LinkedBlockingQueue<>();
private int remaining;
CompletionOrderSpliterator2(List<CompletableFuture<T>> futures) {
this.initialSize = futures.size();
this.remaining = initialSize;
futures.forEach(f -> f.whenComplete((t, __) -> completed.add(f)));
}
@Override
public boolean tryAdvance(Consumer<? super T> action) {
return remaining > 0
? nextCompleted().thenAccept(action)
.thenApply(__ -> true).join()
: false;
}
private CompletableFuture<T> nextCompleted() {
remaining--;
try {
return completed.take();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
}
}
// ...
}And the same idea but with a lock-free ConcurrentLinkedQueue:
final class CompletionOrderSpliterator3<T> implements Spliterator<T> {
private final int initialSize;
private final Queue<CompletableFuture<T>> completed
= new ConcurrentLinkedQueue<>();
private int remaining;
// ...
private CompletableFuture<T> nextCompleted() {
remaining--;
CompletableFuture<T> next = completed.poll();
while (next == null) {
Thread.onSpinWait();
next = completed.poll();
}
return next;
}
// ...
}If we compare the throughput of all of them, we can see the BlockingQueue-based solution scales a bit better with the number of futures in a list: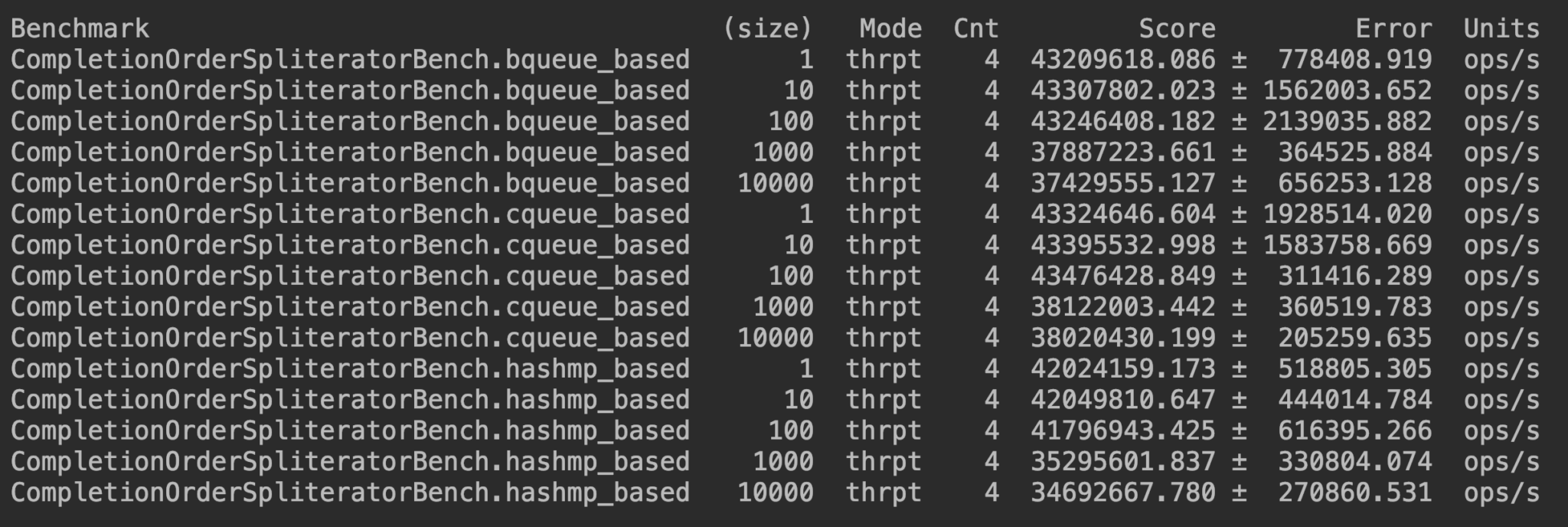
But this benchmark doesn’t cater for the creation time of each Spliterator, so let’s benchmark this case as well:
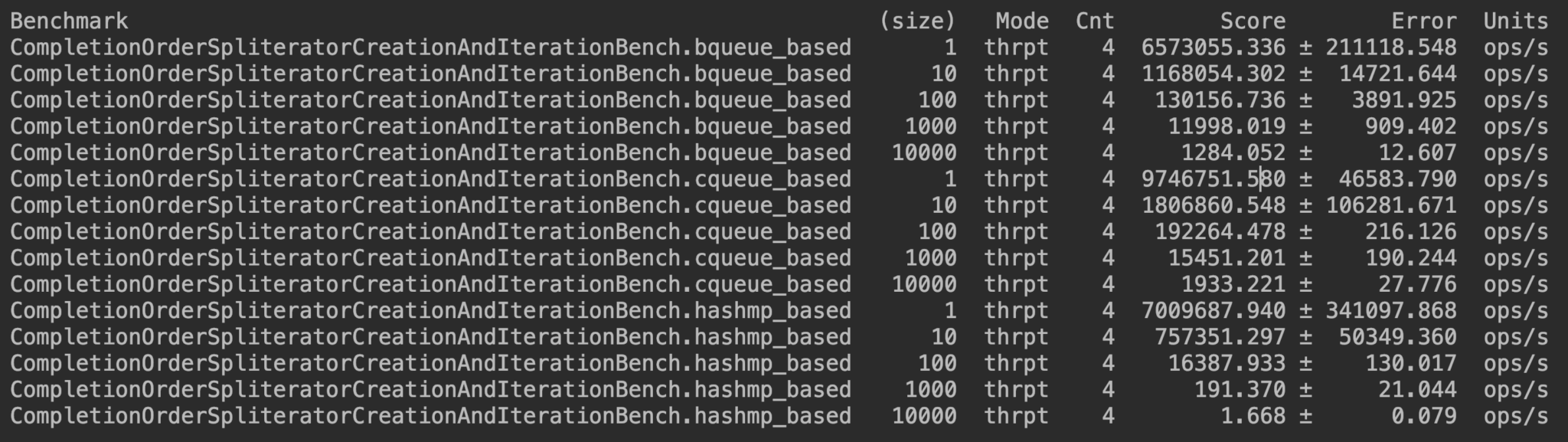
Now, we can see a clear difference in a case resembling a real-life usage. It turns out that the most scalable of them all is the ConcurrentLinkedQueue-based one which clearly outperforms the map-based one:
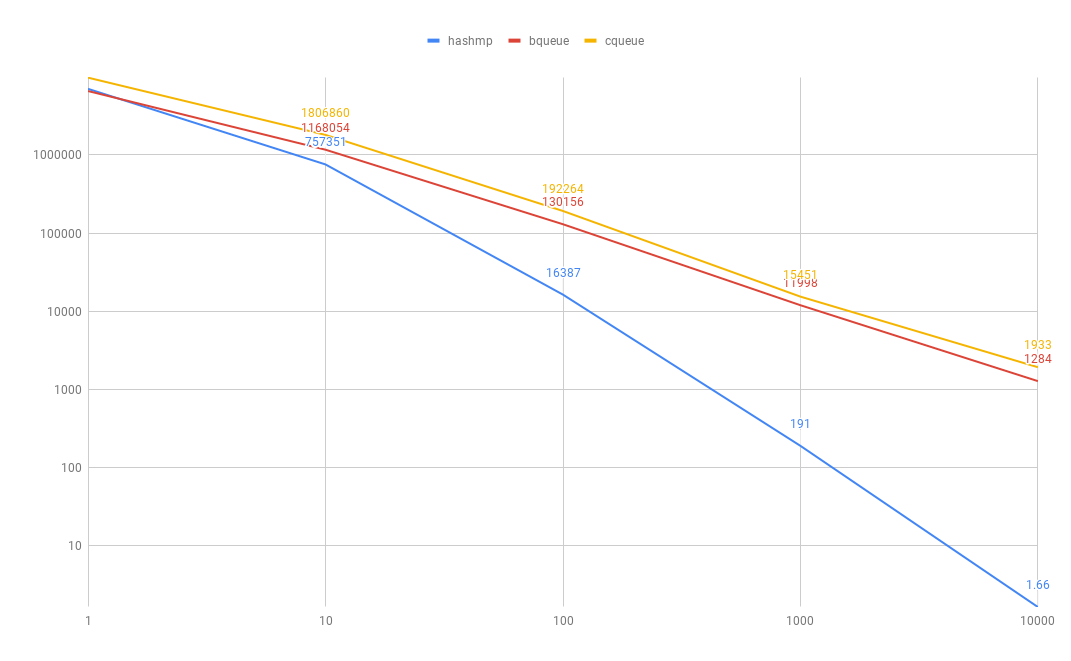
However, in parallel-collectors, I settled on the BlockingQueue-based solution since it avoids busy spinning which is expected to happen a lot when using the library.
The complete working example along with benchmarks can be found on GitHub.
Do you have an idea of how to make it better? Don’t hesitate, and let me know!


