In this article, we’ll see how to increase the performance and cap maximum parallelism by introducing batching to our home-made parallel streams.
This article is a part of the series about parallel collection processing in Java without parallel streams:
Parallel Collection Processing: With Parallel Collectors (3/3)
The Problem
At the end of the previous article, we ended up with fully functional home-made async parallel streams:
CompletableFuture<List<Integer>> results = integers.stream() .map(i -> CompletableFuture.supplyAsync(() -> process(i), executor)) .collect(collectingAndThen(toList(), l -> allOfOrException(l)));
This implementation features some interesting characteristics.
Every element from the source stream is represented as a separate entry in your thread pool’s work queue.
The good thing about it is that threads compete for each item separately which results in a primitive form of work-stealing. If some threads finish early, they continue picking up items from the work queue until it’s empty.
At the same time, the bad thing is that this brings a performance penalty(due to thread contention) in situations where work-stealing doesn’t bring significant value.
Is this something to be concerned about? Let’s see the actual numbers.
Benchmarks
In order to measure the performance overhead, a collection with 1000 elements was processed using an identity function with 1,10,100, and 1000 threads respectively. Minimizing the processing time allows us to focus on the infrastructure overhead instead:
private static final List<Integer> source = IntStream
.range(0, 1000)
.boxed()
.collect(toList());
@Benchmark
public List<Integer> no_batching(BenchmarkState state) {
return ParallelStreams.inParallel(
source, i -> i, state.executor).join();
}
Before we have a look at the results, try to run a thought experiment and then compare your intuition with actual numbers.
How faster will it be to process the collection using 1000 threads instead of one?
Results
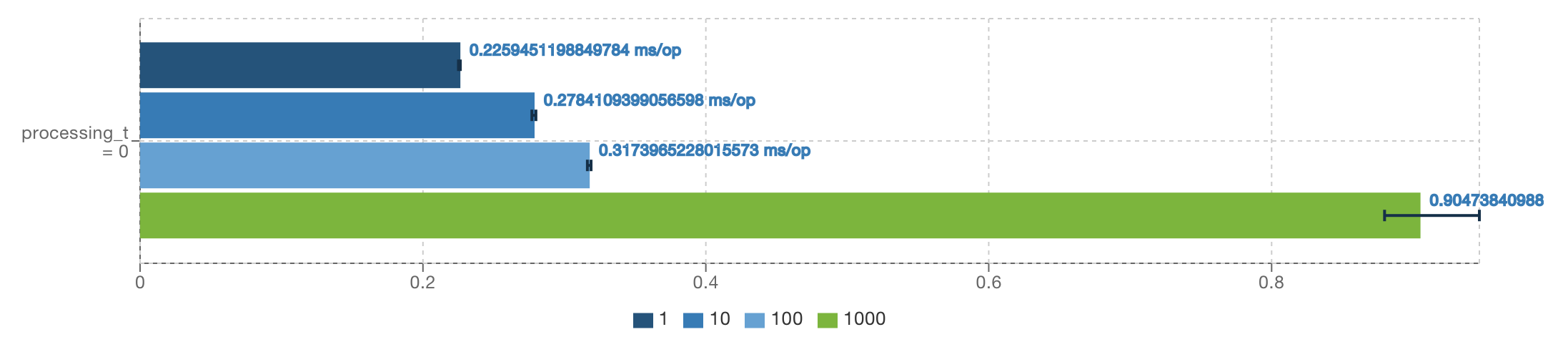
Threads Mode Cnt Score Error Units 1 avgt 5 0.226 ± 0.002 ms/op 10 avgt 5 0.278 ± 0.005 ms/op 100 avgt 5 0.317 ± 0.005 ms/op 1000 avgt 5 0.905 ± 0.097 ms/op Intel i7-4980HQ (8) @ 2.80GHz
Surprised? When the number of threads increases, synchronization costs become more and more significant which makes the case with 1000 threads more than three times slower than single thread processing!
What if we could decrease the overhead(thread contention) by letting individual threads compete for batches instead of individual items?
Introducing Batching
Luckily, introducing batching is less complicated than it sounds.
It’s a good idea to not burden consumers of your API with implementation details so the API remains unchanged. However, we need to introduce one extra parameter to control the number of batches to create(which we would need to introduce anyway later on):
static <T, R> CompletableFuture<List<R>> inParallelBatching(
List<T> source, Function<T, R> mapper, Executor executor, int batches) {
return ...
}
In order to introduce batching, we need to solve three distinct problems:
- How to partition a source collection into a collection of batches
- How to write an adapter for mapping functions so that it processes a collection of elements
- How to combine partial results into a single collection
In order to partition a list of elements, we could reuse the existing splitting mechanism provided by existing Spliterators but in our case, we know that the data structure that we need to partition is ArrayList, so we can write a dedicated partitioning iterator to be able to split a list into N as-equal-as-possible parts:
final class BatchingStream<T> implements Spliterator<List<T>> {
private final List<T> source;
private final int maxChunks;
private int chunks;
private int chunkSize;
private int remaining;
private int consumed;
private BatchingStream(List<T> list, int numberOfParts) {
source = list;
chunks = numberOfParts;
maxChunks = numberOfParts;
chunkSize = (int) Math.ceil(((double) source.size()) / numberOfParts);
remaining = source.size();
}
static <T> Stream<List<T>> partitioned(List<T> list, int numberOfParts) {
int size = list.size();
if (size == numberOfParts) {
return asSingletonListStream(list);
} else if (size == 0 || numberOfParts == 0) {
return empty();
} else if (numberOfParts == 1) {
return of(list);
} else {
return stream(new BatchingStream<>(list, numberOfParts), false);
}
}
private static <T> Stream<List<T>> asSingletonListStream(List<T> list) {
Stream.Builder<List<T>> acc = Stream.builder();
for (T t : list) {
acc.add(Collections.singletonList(t));
}
return acc.build();
}
@Override
public boolean tryAdvance(Consumer<? super List<T>> action) {
if (consumed < source.size() && chunks != 0) {
List<T> batch = source.subList(consumed, consumed + chunkSize);
consumed = consumed + chunkSize;
remaining = remaining - chunkSize;
chunkSize = (int) Math.ceil(((double) remaining) / --chunks);
action.accept(batch);
return true;
} else {
return false;
}
}
@Override
public Spliterator<List<T>> trySplit() {
return null;
}
@Override
public long estimateSize() {
return maxChunks;
}
@Override
public int characteristics() {
return ORDERED | SIZED;
}
}
Implementation considerations of the above will be covered in a separate article.
In order to adapt a mapping function, we need to prepare an adapter that converts Function<T, R> to Function<List<T>, List<R>> which is fairly straightforward:
private static <T, R> Function<List<T>, List<R>> batching(
Function<T, R> mapper) {
return batch -> {
List<R> list = new ArrayList<>(batch.size());
for (T t : batch) {
list.add(mapper.apply(t));
}
return list;
};
}
If we combine the above, we get something like:
static <T, R> CompletableFuture<List<R>> inParallelBatching(
List<T> source, Function<T, R> mapper, Executor executor, int batches) {
return BatchingStream.partitioned(source, batches)
.map(batch -> supplyAsync(
() -> batching(mapper).apply(batch), executor))
.collect(collectingAndThen(toList(), l -> allOfOrException(l)))
...
}
And the last thing left to do is to flatten the result (CompletableFuture<List<List<R>>) into a single list, which can be achieved using Stream#flatMap, or a simple loop. In this case, I choose a loop in order to avoid extra overhead of the Stream API.
So the final result is:
static <T, R> CompletableFuture<List<R>> inParallelBatching(
List<T> source, Function<T, R> mapper, Executor executor, int batches) {
return BatchingStream.partitioned(source, batches)
.map(batch -> supplyAsync(
() -> batching(mapper).apply(batch), executor))
.collect(collectingAndThen(toList(), l -> allOfOrException(l)))
.thenApply(list -> {
List<R> result = new ArrayList<>(source.size());
for (List<R> rs : list) {
result.addAll(rs);
}
return result;
});
}
Benchmarks
Finally, we can compare results with our starting point! Keep in mind that in our benchmarks number of batches is equal to the number of threads.
Again, before we have a look at the results, try to run a thought experiment and then compare your intuition with actual numbers.
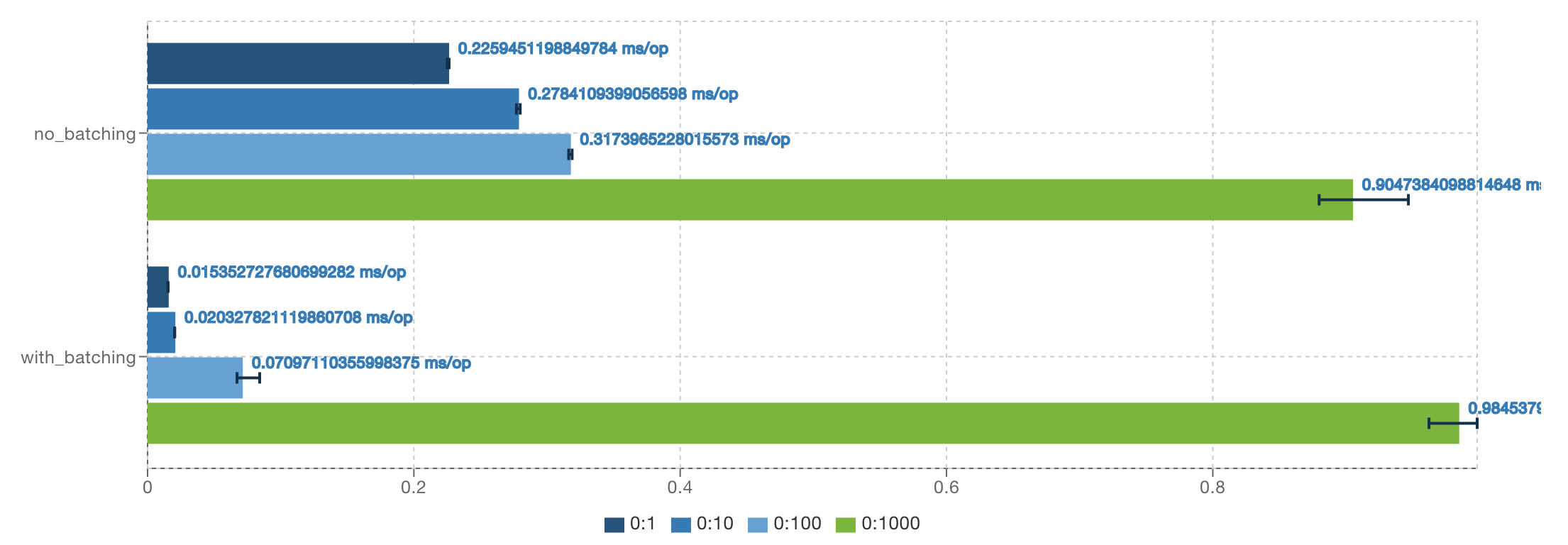
Benchmark Threads Mode Cnt Score Error Units ---- no_batching 1 avgt 5 0.226 ± 0.002 ms/op no_batching 10 avgt 5 0.278 ± 0.005 ms/op no_batching 100 avgt 5 0.317 ± 0.005 ms/op no_batching 1000 avgt 5 0.905 ± 0.097 ms/op with_batching 1 avgt 5 0.015 ± 0.001 ms/op with_batching 10 avgt 5 0.020 ± 0.001 ms/op with_batching 100 avgt 5 0.071 ± 0.028 ms/op with_batching 1000 avgt 5 0.985 ± 0.054 ms/op Intel i7-4980HQ (8) @ 2.80GHz
The result is really impressive. As you can see introducing batching made it possible to decrease overhead in almost all the cases.
In the best-case scenario (1 thread), the overhead was ~9 times lower, and in the worst-case scenario (1000 threads), the overhead was resulting in worse results than without batching at all. At the end of the day, 1000 threads processing 1000 elements results in 1000 batches.
What a great success, isn’t it?
Let me recall the warning you get each time you run JMH:
REMEMBER: The numbers below are just data.
To gain reusable insights, you need to follow up on why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial
experiments, perform baseline and negative tests that provide experimental control, make sure
the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts.Do not assume the numbers tell you what you want them to tell.
The benchmarks we created are telling the truth, but not necessarily the one that we care about(remember the Answer to the Ultimate Question of Life, The Universe, and Everything?).
The relative performance improvement is impressive, but what we really care about is if this improvement is significant enough for our use cases, and our benchmark was designed to show the relative difference between overhead, which doesn’t answer our question!
In our case, we care more about absolute values and not relative ones, so let’s have a look at the speedup we gained in each case:
Benchmark Threads Diff Units ---- with_batching 1 + ~211 ns/op with_batching 10 + ~258 ns/op with_batching 100 + ~246 ns/op with_batching 1000 - ~80 ns/op Intel i7-4980HQ (8) @ 2.80GHz
As you can see, in the best-case scenario, we saved around 258ns.
Depending on your use case, this can be a significant difference or not really. But introducing batching brings other advantages besides offering higher throughput.
Other Considerations
Besides the throughput increase, batching allows you to control the maximum parallelism level.
If you decide to apply the processing in N batches, it also implies that not more than N items will be processed in parallel (assuming that the parallelized action doesn’t orchestrate more parallel processing itself!).
Naturally, you can implement parallelism limits for the non-batching example, but it becomes non-trivial if you want to keep it asynchronous, and requires extra resources (most likely an extra dispatcher thread guarded by a semaphore).
Besides the parallelism level control, batching can give you more predictable latencies when reusing a heavily-shared thread pool.
If no batching involved, each item becomes a separate entry in the thread pool’s work queue, which might result in situations where 99% of the work is already done, but there are other items in the queue that need to be processed first!
And once a batch gets picked up, all the items inside will be processed at once by a single thread.
Another thing to consider is that properly-tuned thread-pools usually feature a fixed-size work queue and that the size(among other parameters) needs to be properly tuned in relation to the expected rate of arrival of new tasks.
Batching generates always N tasks where N corresponds to the number of batches and not the number of all items in the source.
Conclusion
In the next article, we’ll see how to achieve the same by using parallel-collectors.
Code samples can be found on GitHub.