
In this series, we’ll revisit the concept of event sourcing by implementing a PoC of a hypothetical data structure – an event-sourced list, and then improve it further in subsequent articles by making it concurrent and memory-friendly.
Event Sourcing
Over the years, we got used to the fact that most business applications persist state in some external storage which often generates extra work when it comes to ensuring auditability or reconstructing past states. But what if we dropped the assumption that we need to store the state?
For example, imagine storing users’ account balances. That’s as easy as a single database entry:

Event-sourcing is a concept in which, instead of the state, we store state-changing events, and derive the actual state only when needed.
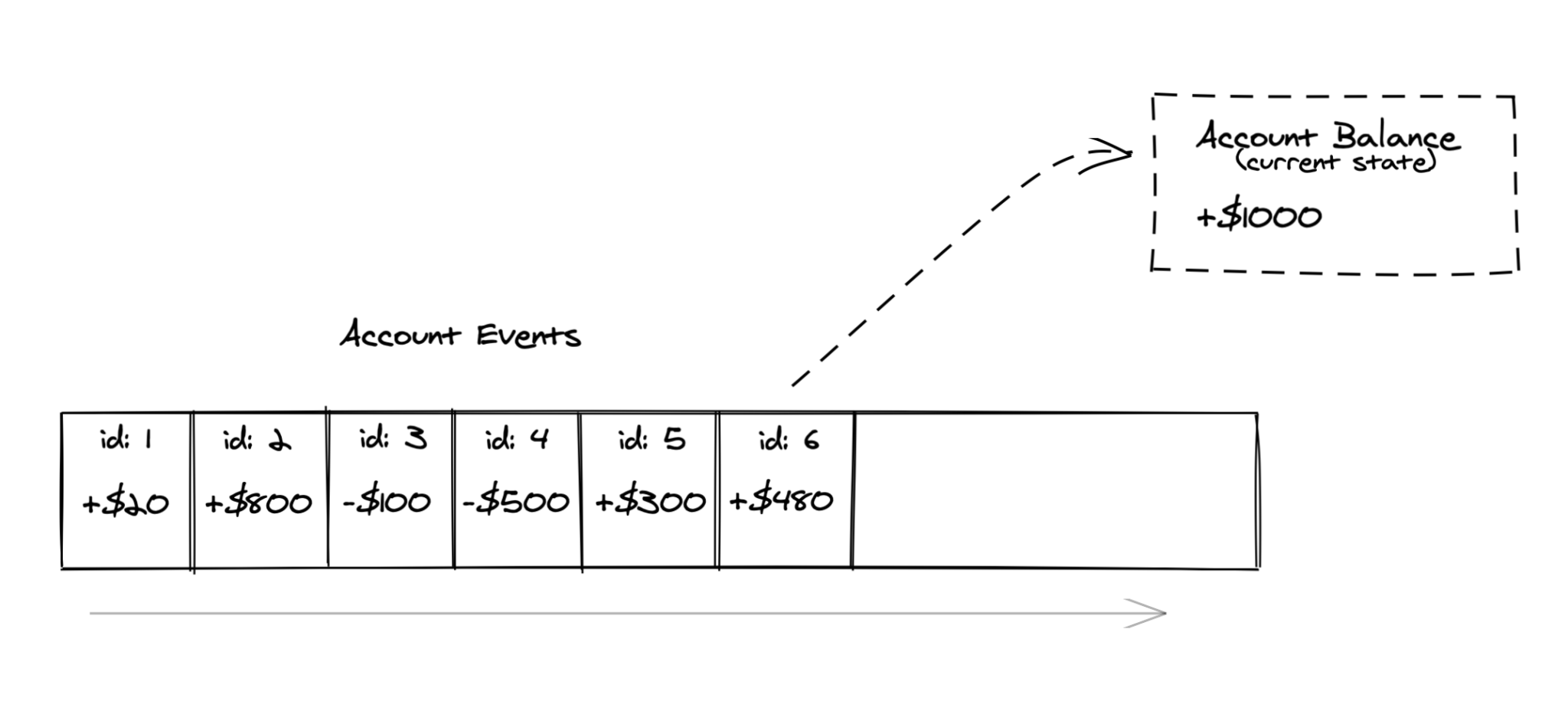
This opens up a lot of possibilities when it comes to auditability and deriving new information!
With event-sourcing, you get access to the whole operation history and not just a raw number. You can trace all past events, past states, that led to that particular value that represents the current state.
Marvelous!
Once we know that, let’s see if we can apply this idea to a common list.
Applying Event-Sourcing to a List
Let’s start by defining the canvas for our implementation:
public class ESList<T> implements List<T> { ... }Just like we established above, in order to implement an event-sourced data structure, we’d need to store state-changing events/operations and not the state itself, and then run our methods against the state recreated on the spot.
In order to achieve this, we need to:
- define a contract for our events/operations
- define a storage container for our historical events
- implement event handling logic
- implement event replay logic
The internal event log is the core of our implementation. This is the history of all modifications applied to the data structure and can be represented as a simple list:
private final List<ListOp<T>> opLog = new ArrayList<>();
An operation is effectively just a function that takes some list and returns the result of such operation:
interface ListOp<R> {
Object apply(List<R> list);
}So, an operation representing the addition could be implemented as:
class AddOp<T> implements ListOp<T> {
private final T elem;
AddOp(T elem) {
this.elem = elem;
}
@Override
public Object apply(List<T> list) {
return list.add(elem);
}
@Override
public String toString() {
return String.format("add(element = %s)", elem);
}
}Now, whenever we implement any state-changing method, we simply need to create a representation of the operation, store it, and apply to a recreated state so that we can return the result of the operation:
@Override
public boolean add(T t) {
return (boolean) handle(new AddOp<>(t));
}Now, if we wanted to recreate the state of the list at any point in time, we’d need to rerun all the operations since the beginning of time.
Better be safe than sorry so it’s better to return a result wrapped in an Optional instance:
public Optional<List<T>> snapshot(int version) {
if (version > opLog.size()) {
return Optional.empty();
}
var snapshot = new ArrayList<T>();
for (int i = 0; i <= version; i++) {
try {
opLog.get(i).apply(snapshot);
} catch (Exception ignored) { }
}
return Optional.of(snapshot);
}
public List<T> snapshot() {
return snapshot(opLog.size())
.orElseThrow(IllegalStateException::new);
}The empty catch block might look controversial, but it’s crucial when it comes to tracing failures. We’ll add some logging later on.
And now we can finalize the event handling logic. Notice that we need to first recreate the current state before adding the operation to the log:
private Object handle(ListOp<T> op) {
List<T> snapshot = snapshot();
opLog.add(op);
return op.apply(snapshot);
}And now, all query methods of List interface will need to recreate the state first:
@Override
public int indexOf(Object o) {
return snapshot().indexOf(o);
}
@Override
public int lastIndexOf(Object o) {
return snapshot().lastIndexOf(o);
}
@Override
public ListIterator<T> listIterator() {
return snapshot().listIterator();
}
// ...Would be also handy to have a method informing us how many versions of the data structure exists:
public int version() {
return opLog.size();
}Additionally, to make it convenient for us to observe changes, let’s add one extra method to display the history of all operations:
public void displayLog() {
for (int i = 0; i < opLog.size(); i++) {
System.out.printf("v%d :: %s%n", i, opLog.get(i).toString());
}
}And now, let’s see it in action by performing some modifications and eventually clearing the list:
public static void main(String[] args) {
ESList<Integer> objects = ESList.newInstance();
objects.add(1);
objects.add(2);
objects.add(3);
objects.addAll(List.of(4, 5));
objects.remove(Integer.valueOf(1));
objects.clear();
objects.displayLog();
System.out.println();
for (int i = 0; i < objects.version(); i++) {
System.out.println("v" + i + " :" + objects.snapshot(i).get());
}
}Despite the fact that by clearing the list we got back to square one, we can see that the whole history is maintained and we managed to recreate all existing versions of the data structure:
v0 :: init[] v1 :: add(element = 1) v2 :: add(element = 2) v3 :: add(element = 3) v4 :: addAll([4, 5]) v5 :: remove(1) v6 :: clear() v0 :[] v1 :[1] v2 :[1, 2] v3 :[1, 2, 3] v4 :[1, 2, 3, 4, 5] v5 :[2, 3, 4, 5] v6 :[]
And here we are! That’s the basic idea of event-sourcing.
Naturally, this implementation has multiple downsides and is definitely nowhere near being production-ready. It’s not only not thread-safe, but an internal event log is a source of a memory leak.
Not even mentioning the fact that replaying events before each operation is dreadful inefficient but serves us well as educational material.
Conclusion
It might sound trivial, but event-sourcing has its downsides, so please make sure to evaluate the pros and cons before rushing with it for your next application.
Code snippets can be found over on GitHub.
In the next article, we’ll go through an exercise of making that data structure concurrent. That’s not essential to understanding the concept, but it should be pure fun anyway!


